Measuring production code coverage with JaCoCo
Microservices is the new fancy way of doing applications. Yet, most companies still have big …

At ContaAzul, we have several old pieces of code that are still running in production. We are committed to gradually re-implement them in better ways.
One of those parts was our distributed locking mechanism and me and @t-bonatti were up for the job.
In normal workloads, we have two servers responsible for running previously scheduled tasks (e.g.: issue an electronic invoice to the government).
An ideal scenario would consist of idempotent services, but, since most of those tasks talk to government services, we are pretty fucking far from an ideal scenario.
We cannot fix the government services’ code, so, to avoid calling them several times for the same input (which they don’t like, by the way), we had think about mainly two options:
One server would probably not scale well, so we decided that synchronizing work between servers was the best way of solving this issue.
At the time, we also decided to use Hazelcast for the job, which seemed reasonable because:
The architecture was something like this:
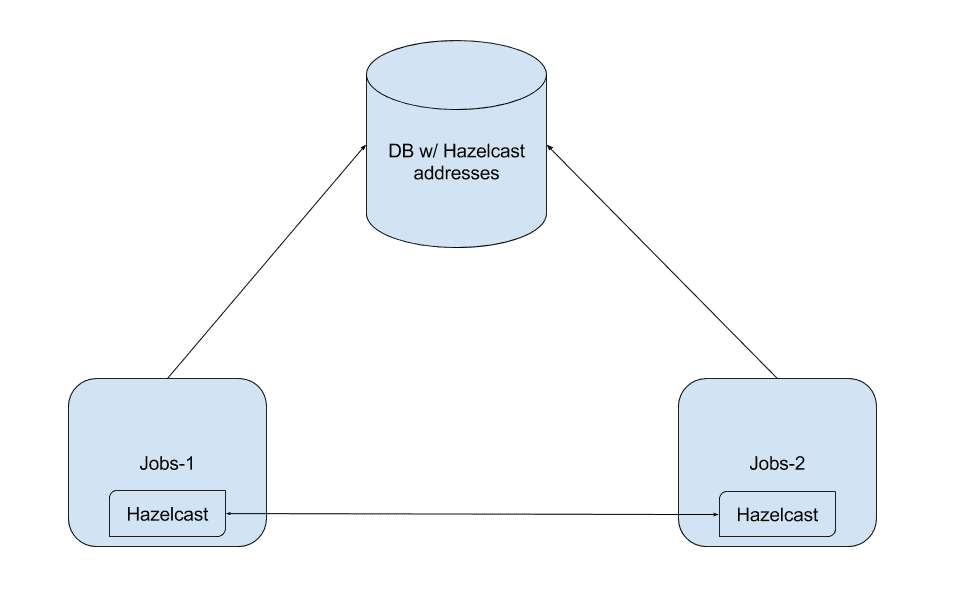
Architecture with Hazelcast.
Basically, when one of those scheduled tasks servers (let’s call them jobs) went up, it also starts a Hazelcast node and register itself in a database table.
After that, it reads this same table looking for other nodes, and synchronizes with them.
Finally, in the code, we would basically get a new ILock from Hazelcast API and use it, something like this:
if (hazelcast.getLock( jobName + ":" + elementId ).tryLock() {
// do the work
}
There was, of course, an API around all this so the developers were just locking things, and may not know exactly how.
This architecture worked for years with very few problems and was used in other applications as well, but still we had our issues with it:
So, we decided to move on and re-implement our distributed locking API.
The core ideas were to:
/.*hazelcast.*/ig;tl;dr, this:
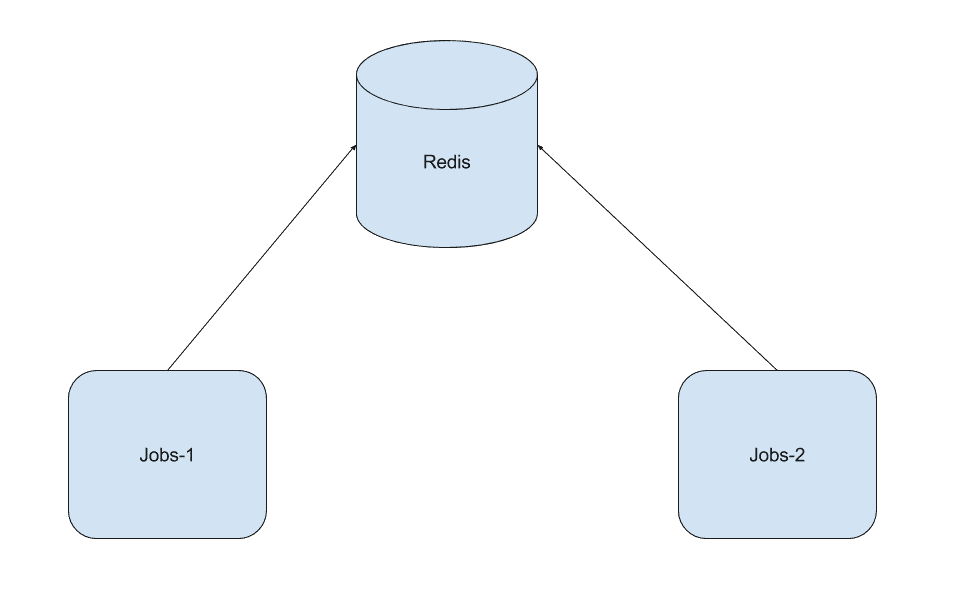
Architecture with Redis.
The reasons behind this decision were:
But, of course, everything have a bad side:
We called this project “Operation Locker”, which is a very fun Battlefield 4 map:

Operation Locker from Battlefield 4.
Our distributed lock API required the implementation of two main interfaces to change its behavior:
JobLockManager:
public interface JobLockManager {
<E> boolean lock(Job<E> job, E element);
<E> void unlock(Job<E> job, E element);
<E> void successfullyProcessed(Job<E> job, E element);
}
and JobSemaphore:
public interface JobSemaphore {
boolean tryAcquire(Job<?> job);
void release(Job<?> job);
}
We looked up several Java Redis libraries, and decided to use Redisson, mostly because it seems more actively developed. Then, we created a JBoss module with it and all its dependencies (after some classloader problems), implemented the required interfaces and put it to test, and, since it worked as expected, we shipped it to production.
After that, we decided to also change all other apps using the previous version of our API. We opened pull requests for all of them, tested in sandbox, and, finally, put them in production. Success!
We achieved a simplified architecture, reduced a little our time-to-production and improved our monitoring.
All that with zero downtime and with ~4k less lines of code than before.