Making Python respect Docker memory limits
If you run Python inside containers, chances are you have seen Linux’s OOMKiller working …

I recently fall into a trap using Traefik as the ingress controller in one cluster. I decided to write about it with hopes it maybe help someone else.
We got the architecture like this:
Cloudflare -> Traefik LoadBalancer -> Traefik Pods -> App Pods
Traefik was running in a node pool that had only non-preemptible machines. The app pods were running in a mix of preemptible and not preemtible.
We also have other things running, so, in reality, we had a lot of nodes running neither the app nor Traefik pods, just kube-system stuff, monitoring, batch jobs and so on.
Clients would sometimes report that Cloudflare returned a HTTP 520.
520 is not specified by any spec, but is used by Cloudflare to indicate “unknown connection issues between Cloudflare and the origin web server”.
We though maybe something was up on our app, or maybe even on Traefik instances. We looked into our logs and monitoring, but couldn’t find anything relevant.
I was pretty much losing my hair and was sure something was going on with Traefik and that for some reason I couldn’t find what it was.
Because of that, I decided to try to create a GCE ingress — which translates to GCE Load balancer directly.
Then it hit me… after days of looking into things that had nothing to do with the problem, as usually, it was something obvious (once you get it).
Basically, any node can route to a pod running in any other node.
That is handled by kube-proxy and iptables:
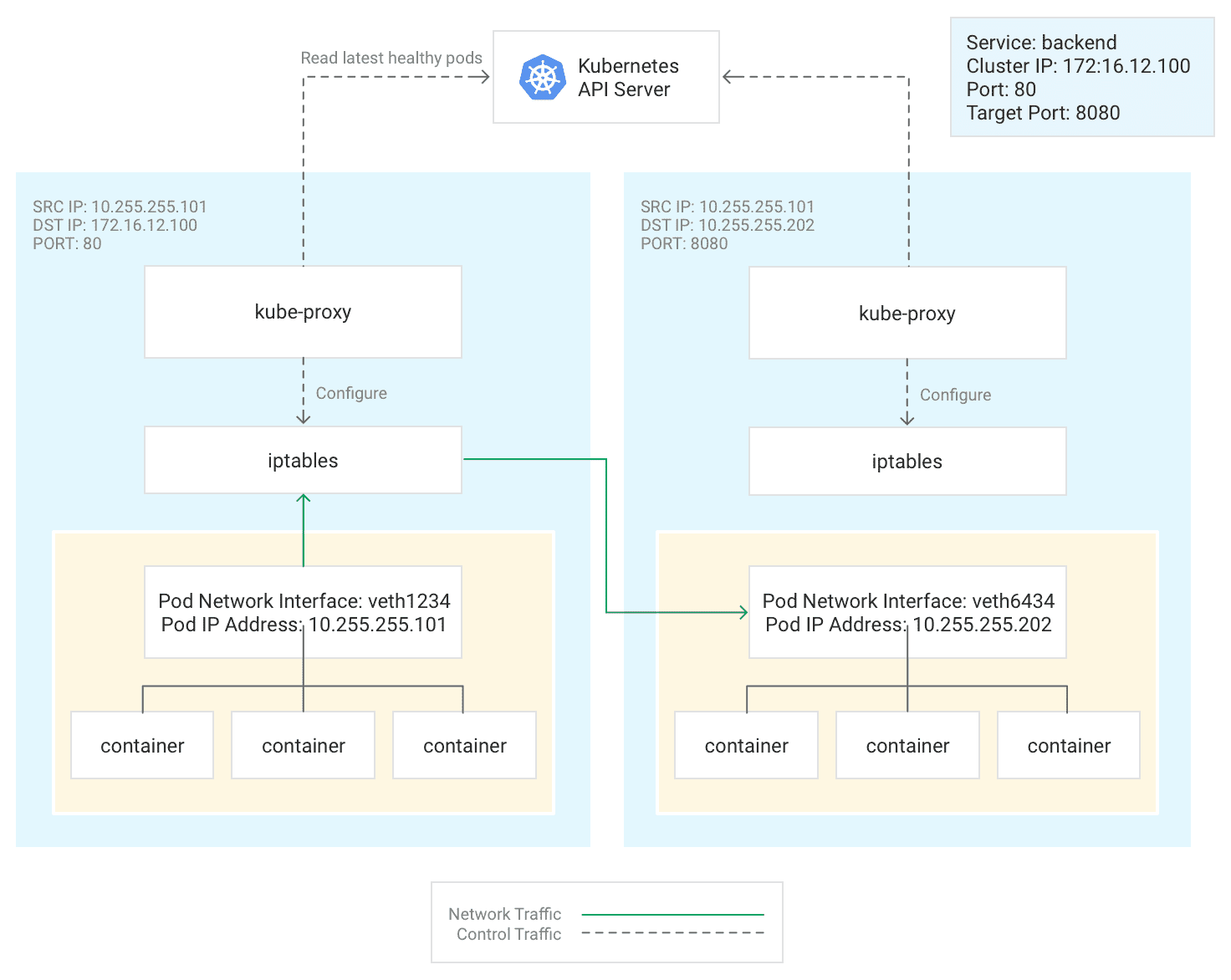
Original: https://cloud.google.com/kubernetes-engine/docs/concepts/network-overview
That, plus the following screenshot made clicked me:
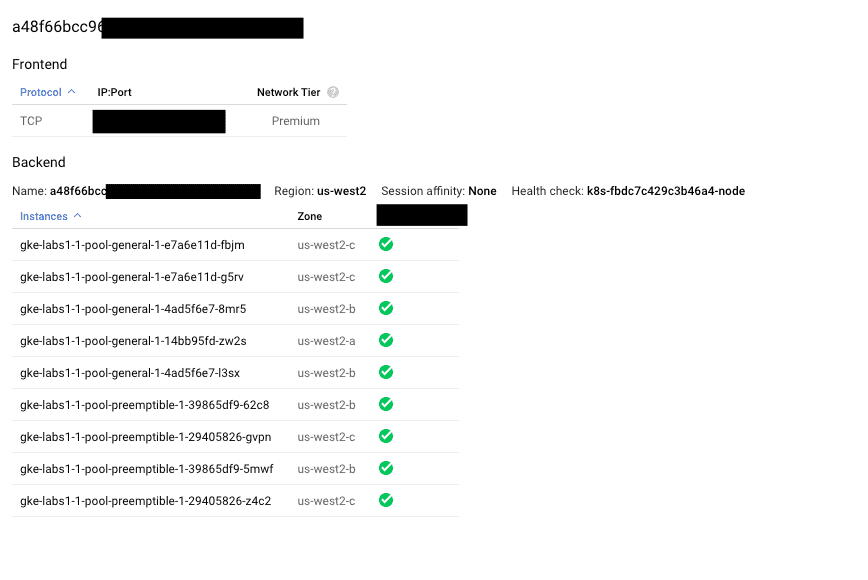
One of our load balancers showing all nodes as green, even the ones with no Traefik pods running...
Even though we had Traefik running only on non-preemptible nodes, all nodes, including the preemtible ones, were receiving traffic from the load balancer.
From there it is straightforward to figure out what can happen:
myapp.fooSo, what we need, ideally, is to have only the nodes that are actually running Traefik to be “green” on the load balancer, all others must fail the healthchecks.
After digging a bit, I found out about a setting called externalTrafficPolicy.
The default for it is Cluster, which makes the traffic being NATed. The main reason to change this is, usually, because you want to use traefik.ingress.kubernetes.io/whitelist-source-range to filter traffic, but, since by default the requests get NATed, you can’t, because you won’t get the correct client IP.
Setting externalTrafficPolicy to Local has two effects:
traefik.ingress.kubernetes.io/whitelist-source-range now works;Which, yeah, fixes our issue.
Literally one line of code…
After hours and hours investigating…
🤷♂️
It seems to me Local should be the default option instead of Cluster, as it seems to be what you will usually want — maybe this is an old default they don’t want to change, didn’t get into it.
Changing from Cluster to Local in a live cluster will cause some requests to fail. On some clusters it was only for a few seconds, in another one it took almost 1 minute to stabilize.
Beware.