Making Python respect Docker memory limits
If you run Python inside containers, chances are you have seen Linux’s OOMKiller working …

We are running Kubernetes on both sandbox and production for some months now. Our production cluster is still small, with few services running on it, but, most of our sandbox environment is running on a Kubernetes cluster on AWS.
We created the clusters with Kops (which is great by the way), but we soon realized that the sandbox cluster was too expensive for our needs.
In this article I’ll describe the strategies we used to decrease our sandbox cluster costs by ~70%.
The first item here is probably the most important one: tune the requests and limits of your services.
You can read the docs if you want, but, tl;dr: requests are the minimum resources a pod needs to be scheduled to a node and limits are the maximum resources a pod is allowed to use.
The syntax looks like this:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
name: myapp
spec:
containers:
- name: myapp
image: blah/myapp:latest
resources:
limits:
cpu: 1
memory: 1.2Gi
requests:
cpu: 100m
memory: 900Mi
But, how do you find the correct values?
The best way I found is to:
requests values;limits values;Of course, this isn’t perfect. Some times it will not be enough and other times it will be too much. Apps also change, and their resource usage tend to change as well.
You need to constantly keep an eye on that.Load balancersAWS Elastic LoadBalancers costs almost $20/mo. At the beginning, we created all the services with the service.beta.kubernetes.io/aws-load-balancer-internal annotation set, ending up with tons of ELBs and spending a lot of money.
Later on, we created an Ingress controller with nginx, and most of our services are served through it. So, instead of having a ELB for each service, we now have a single ELB for the Ingress. All requests pass through it, with nginx doing the work of sending them to the right pods.
I recommend you to read this really good article about how Ingress works, and, of course, the documentation.
PS: Ingress controllers may be a little confusing at the beginning, don’t worry.
During the day it is common that someone deploys a service to test something, and later move on to the next task, while the pod is still there, running, with no usage at all.
To improve that, we wrote the following bash script, and put it in a crontab every 10 minutes:
#!/bin/bash
set -eo pipefail
ingress="$(kubectl get pods --output=jsonpath='{.items[*].metadata.name}' |
xargs -n1 | grep "ingress-nginx" | head -n1)"
# cache all hosts that pass through the ingress
hosts="$(kubectl get ingress nginx-ingress \
--output=jsonpath='{.spec.rules[*].host}' | xargs -n1)"
# cache pods
pods="$(kubectl get pods)"
# cache ingress logs of the last 90min
logs="$(kubectl logs --since=90m "$ingress")"
# iterate over all deployments
kubectl get deployment --output=jsonpath='{.items[*].metadata.name}' |
xargs -n1 |
while read -r svc; do
# skip svc that don't have pods running
echo "$pods" | grep -q "$svc" || {
echo "$svc: no pods running"
continue
}
# skip svcs that don't pass through the ingress
echo "$hosts" | grep -q "$svc" || {
echo "$svc: not passing through ingress"
continue
}
# skip svcs with pods running less than 1h
echo "$pods" | grep "$svc" | awk '{print $5}' | grep -q h || {
echo "$svc: pod running less than 1h"
continue
}
# check if any traffic to that svc was made through the ingress in the
# last hour, scale it down case none
echo "$logs" | grep -q "default-$svc" || {
echo "$svc: scaling down"
kubectl scale deployments "$svc" --replicas 0 --record || true
}
done
It will scale down to 0 replicas deployments whose pods didn’t had accesses through our ingress in the last 90 minutes and are on for less than 1 hour.
With that in place, we could run with less nodes some times of the day, but, changing the desired amount of machines on the AutoScale Groups manually would be a lot of work, don’t you think?
With the requests and limits well defined, the Kubernetes scheduler can take better decisions on where to schedule pods. We are also shutting idle pods down, so, the best place to schedule a pod may change over time, generating idle nodes over times.
Kubernetes contrib has this really good piece of software called cluster-autoscaler. The tool’s documentation itself is very good, and there is a guide on how to run it on AWS.
The only problem we found is that it is usual for the Kubernetes scheduler to spread non-deamons set, non-mirrored, kube-system pods across serveral nodes, which causes cluster-autoscaler to not shut any of them down.
Our sandbox usage is very seasonal: during the night there is usually no pods running nor any activity, but, because of this behavior, it was common to still run all the night with 2 almost-idle nodes.
To workaround this, we added a Scheduled Action to the AutoScale Group, which sets the desired value to 1 node at 9PM.
This may cause some downtime until the pods are scheduled on the remaining node, but it is not a problem, since no one is using them at that time.
As I said before, most of our services are written in Java, and usually they use “a lot” of memory (~700Mb+), while not so much CPU most of the time (~50m).
We were using c4.xlarge machines, with lots of CPU and not so much memory, so, we end up with memory being the bottleneck, causing the cluster-autoscaler to launch more instances because there were no memory enough, while having a lot of idle CPU time.
So, we looked for other machine types and end up deciding to use r3.large machines:
c4.xlarge: 4 vCPUS, 7.5 Gb - 145.67 USD/mor3.large: 2 vCPUS, 15.2 Gb - 121.52 USD/moWith that change, we could schedule more pods per node while running with fewer nodes than before. Win-win.
We started the cluster with really small disks (30Gb if I recall correctly). Disks this size provide only 100 IOPS, which was not enough for our needs.
We then went wrong to the other side, increasing the node disks to 200Gb, and thus 600 IOPS.
That worked well, but each of those volumes costs $17/mo, and we were not really using all that power.
We finally reached the middle-term with 100Gb disks, providing 300 IOPS.
Each of them costs only $7/mo, which saves us $10/disk/mo.
We decided to try to spend even less, so we looked into the spot market.
We had a really good surprise looking into the r3.large instance price history:
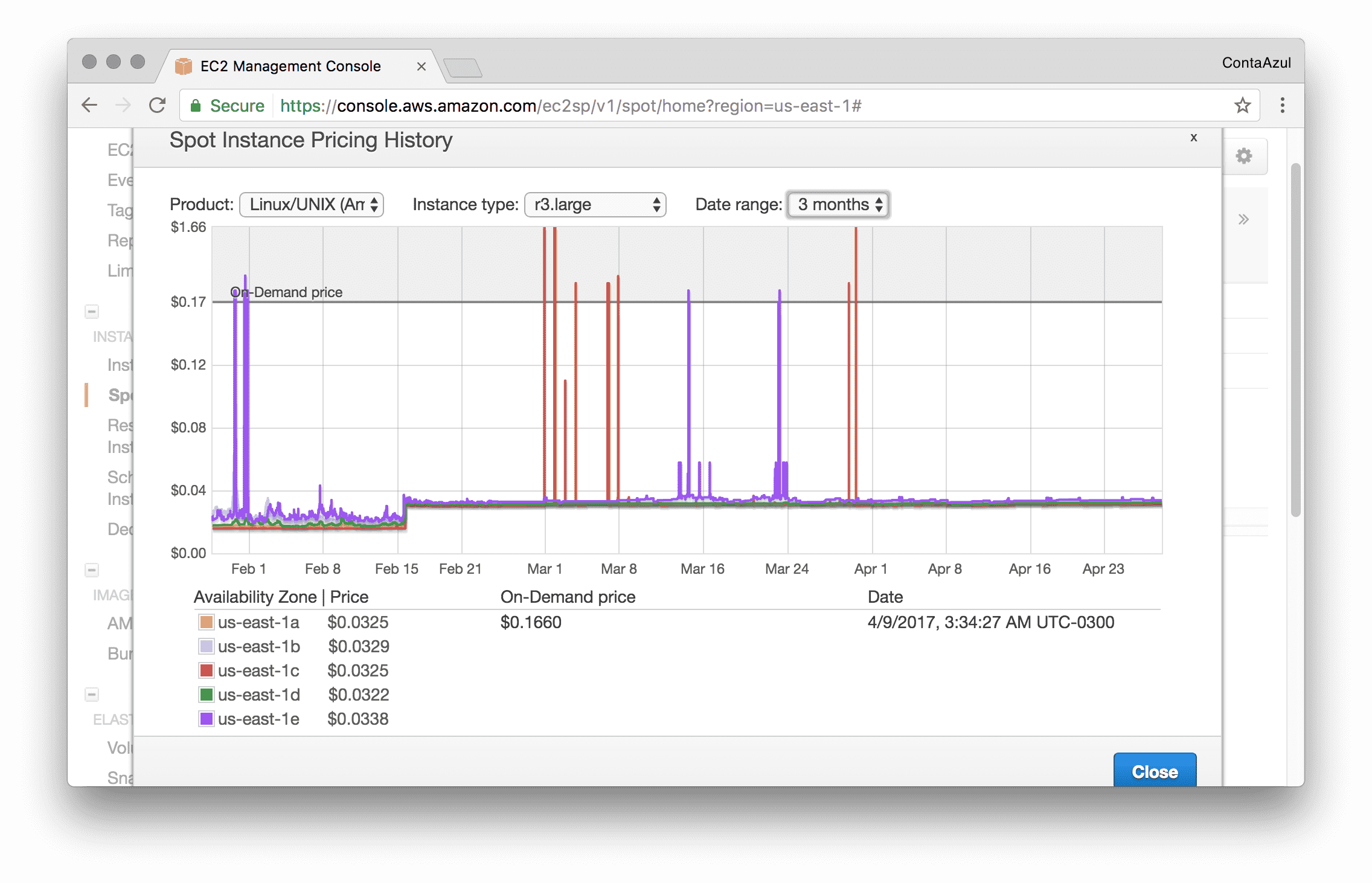
Spot instance pricing history for r3.large
Almost 80% cheaper!
We then set our bid a little higher than the on demand price in order to not have our instances killed in some crazy price spike, and that was it.
Remember that the scale up may take a little longer, since AWS has to process your spot requests before launching the instance.
If you are on single-master setup, it may be a good decision to buy a reservation for that instance.
For example, a t2.medium costs $34.41/mo if on demand and only $26.28/mo on a 1 year no upfront reservation - ~24% cheaper.
If you do not wish to use spot instances for the nodes, you can buy reservations for them instead and save some money as well.
Some of the strategies I explained here can be safely used in production clusters. The attention points are, in my opinion:
With all those changes in place, we are now spending around $7/day on our cluster on business days.
Brotip™: Add KubernetesCluster as a cost allocation tag in your AWS account, so you can generate useful reports like this one:
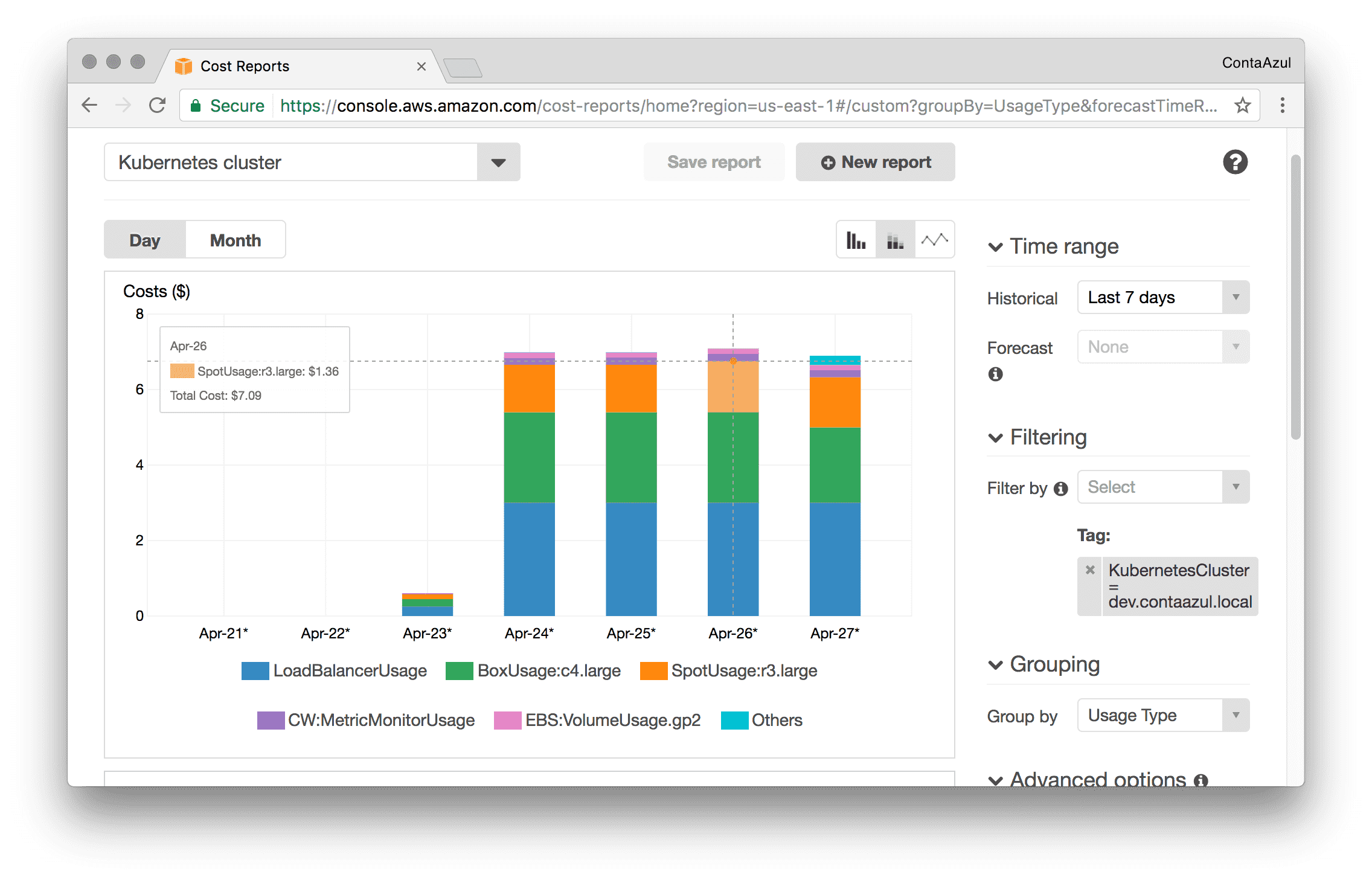
AWS Costs report
As you can see, I only realized that after some time, so, I don’t have the precise daily costs before all these changes, but I estimate that we were spending at least $30/day, ~70% more than we are now.
What about you? What are your strategies for better use computational resources (and money)?